SoundProcesses
A framework for describing, connecting, and manipulating sound processes. The manipulations are centered around core cells called processes which are building blocks associated with a real-time sound synthesis function. All actions are transactionally encapsulated, providing the notion of a logical time instant at which multiple actions happen together. The sound synthesis back-end is ScalaCollider. This project exists in two major versions:
Older version (0.34)
This version is based on an ephemeral view of these processes, where all actions are happening instantly, and sound parameters possess no notion of passing time. This version is very stable and has been used in various projects, such as my pieces «Dissemination», «Writing Machine», and «Inter-Play/Re-Sound»
New version
The new version embodies the research I conducted for my PhD. Transactions are handled by a framework called 'LucreSTM' which allows the selection both of ephemeral and confluently persistent semantics. In the latter case, all manipulations are recorded in a versioning system, allowing to view the musical structure at arbitrary previous points in time, as well as combining elements across different versions. This time axis is called 'creational time'.
Secondly, a full bi-temporal system is established by describing sound parameters as functions of 'performance time'. The functions are called graphemes and may contain both breakpoint data as well as sampled (audio file) data. Graphemes are entities separated from the sound processes. Parameter values may be described with dataflow-like expression trees. The musical data structure as a 'model' is largely separated from the actual real-time sound synthesis which is implemented as a sort of 'aural view'.
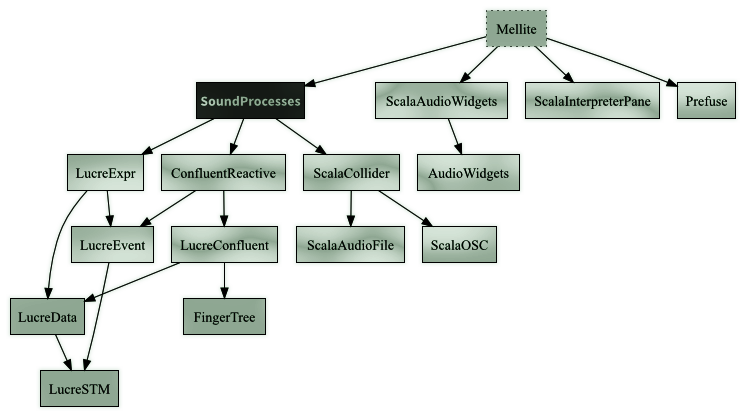
This version is still highly experimental, but has already been successfully been used in my piece «Voice Trap». A graphical front-end, 'Mellite', is currently a work in progress. The following is a link to the project as well as a diagram outlining the sub-modules involved: